Χ��AI ELF OpenGoȫ�濪Դ ��Ԩ������ѵ������
|
�����ţ��ֻ������棩���ԡ�������������Ȩ�顾�����������У�ԭ�ĵ�ַΪ��
http://sports.sina.com.cn/go/2019-02-14/doc-ihrfqzka5784014.shtml |
��վּ�ڰ�������ͨ����վ���ֻ����˽�ҵ����Ѷ��������Ȩ�������֮�����ǽ��ڵ�һʱ��ɾ����
|
|
����ͼ ������Դ������λ
�������ڣ���ʱ����ء������飬�㶼�ܺ��ʶ���Χ��AI��ս����һ���ˡ�
���������Facebook��Χ��AI ELF OpenGoȫ�濪Դ������ELF OpenGo���հ汾ģ�ͣ����˶�����ELF OpenGo���塣
�������ˣ���Ҫ��ELF OpenGo�������������������̾�����������㣬��������Ժ��רҵΧ��ѡ��Ҳ������ˡ������־��������נ������ѵ���������λרҵ���ֶ�սʱ��ELF OpenGo��20��0�ijɼ���Ӯ��Ӯ��
��������Χ��AI��С��������ǰ��Leela Zero��Ҳ��18��980�ijɼ���ELF OpenGoԶԶ˦������
�������죬Facebook������ELF OpenGo���о����ģ�������AlphaGo Zero��AlphaZero��Դ��ַ��
 ����15�죬15�� ����15�죬15��
�����ڽ���շ���������ELF OpenGo�� An Analysis and Open Reimplementation of AlphaZero�У�Facebook�о���Աȫ����¶��ELF OpenGo��ѵ�����̡�
 ����ELF OpenGo��ȥ�굮���ġ���ʱ��Facebook�Ľ����Լ�������Ϸ�Ļ���ѧϰ���ELF������������ʵ����DeepMind��AlphaGoZero��AlphaZero���㷨���õ������Χ��AI ELF OpenGo�� ����ELF OpenGo��ȥ�굮���ġ���ʱ��Facebook�Ľ����Լ�������Ϸ�Ļ���ѧϰ���ELF������������ʵ����DeepMind��AlphaGoZero��AlphaZero���㷨���õ������Χ��AI ELF OpenGo��
����������ʾ��ѵ�����̴���ѭ��AlphaZero��ѵ�����̡�
������AlphaZero��5000�����Ҷ��ĵ�TPU��64��ѵ��TPU��ͬ������ѵ�����̹�����2000��Ӣΰ��GPU���ͺž�ΪӢΰ��Tesla V100 GPU���ڴ�Ϊ16GB���ܹ�ѵ����15�졣
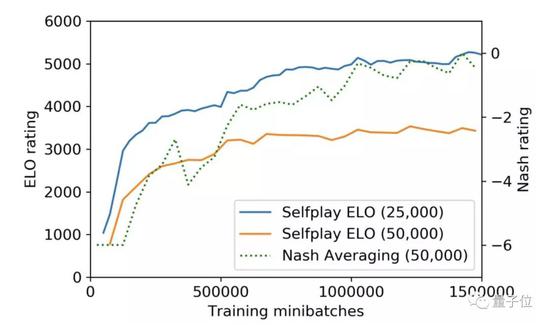 �����о���Ա��Ӧ����ELF OpenGo�����������������ͻ�� �����о���Ա��Ӧ����ELF OpenGo�����������������ͻ��
����һ����
�����о���Ա������һ������AlphaZero����������������2000��GPU����ѵ����9������20�������ģ�͵ı����Ѿ�����������ˮƽ��
��������о���Ա�ṩ��һЩԤѵ��ģ�͡������2000������Ҷ��ĵ�ѵ���켣���ݼ�����ѵ����
�����ڶ�����
-
��ѵ�������У��о���Ա�۲쵽��ELF OpenGo������ģ����ȣ�ˮƽ�仯�Ƚϴ�ʹѧϰ���ȶ�������Ҳ�����¸�����
-
���⣬ģ����Ҫ����ǰհ����������һ������ô��ʱ��ģ��ѧϰ�ٶȽ�����ѧϰ�ѶȺܴ�
-
����֮�⣬�о���Ա����̽��������Ϸ�IJ�ͬ��AIѧ����������巨���ٶȡ�
������������
�����о���Ա���֣���������ģ�Ͷ��ԣ��Ծ��мӱ�rolloutˮƽ��Լ����200 ELO��AI�ķ��ӻ��ܵ�ģ�����������ơ�
����Ŀǰ��ELF OpenGo�����ġ�ģ�͡�ʵ�ִ��롢���Ҷ������ݼ�����������ļ�¼���Ѿ�ȫ����������ַ�ɵ���ĩѰ�ҡ�
���������Ŷ�
������ƪ��������Facebook�˹������о�����FAIR����һ�����ڻ���ѧϰȦ��һ����Ϥ�����֣���Ԩ����
������Ԩ���ӿ��ڻ�÷¡��ѧ��CMU����ҵ����Ԩ�������ȸ����˳���Ŀ�飬�������ת��Facebook�˹������о�����FacebookΧ��AI Darkforest������о��������˺�����һ��Ҳ����Ԩ����
 ������ ��Ԩ������ ������ ��Ԩ������
������Ԩ��Ҳһֱ��Ծ��֪�������˹����ܡ����ѧϰ���������ش��ߣ���֪��er���еĴ���
����ȥ�꣬��Ԩ���ع��Լ�������Ĺ��������ѧϰ���ĵ����¡���ʿ����֮��������ܽᡷ������ΪȦ�ڵı������£����������ٴα�Ȧ�ۣ���������ඥ��
 �������Ķ���Jerry MaҲͬ��Ϊ���ᣬ��Facebook������ʾ��2018�꣬Jerry Ma�ոձ��α�ҵ����ù����ѧ����ѧ�ŵ���ѧѧʿ˫ѧλ��Ŀǰ����Facebook�о����̸����ˡ� �������Ķ���Jerry MaҲͬ��Ϊ���ᣬ��Facebook������ʾ��2018�꣬Jerry Ma�ոձ��α�ҵ����ù����ѧ����ѧ�ŵ���ѧѧʿ˫ѧλ��Ŀǰ����Facebook�о����̸����ˡ�
 ������ Jerry Ma ������ Jerry Ma
������Ͳ������β�С��
����������
����GitHub��ַ��https��//github.com/pytorch/ELF
�������ĵ�ַ ��https��//arxiv.org/abs/1902.04522v1
����Facebook���ͽ��ܣ�https��//ai.facebook.com/blog/open-sourcing-new-elf-opengo-bot-and-go-research/
����ELF OpenGo������https��//facebook.ai/developers/tools/elf-opengo
�������⣬������Դ�Windowsϵͳ�ĵ��ԣ���������������������������塣���ص�ַ��
����https��//dl.fbaipublicfiles.com/elfopengo/play/play_opengo_v2.zip
������ �� ��
|

 ����
���� ����
���� ����
���� ����
���� ����
���� ����
����